
The Problem
A paralegal opens a scanned police report. Messy handwriting, faded stamps, inconsistent formatting. They spend the next 30 to 60 minutes squinting at the PDF, manually typing every detail into Clio, generating a retainer agreement, composing an email, setting a statute of limitations reminder, and uploading documents. By the time they hit send, the prospect has already signed with the firm that responded first.
This is the daily reality at most PI firms. And the cost is not just labor. Research shows that PI firms responding within one minute convert 391% more leads than those responding in five minutes. Every minute a police report sits on a paralegal’s desk is a case that might never get signed. The bottleneck is not the law. It is the intake.
We built a system that eliminates that bottleneck. Upload a police report PDF, and seconds later: 18 Clio custom fields populated, statute of limitations on the calendar, retainer agreement generated and uploaded to the matter, personalized client email sent with a dispute narrative pulled from both drivers’ statements, and the communication logged. Zero manual steps between PDF upload and a fully documented Clio matter.
What We Built

Two n8n workflows totaling 23 nodes that orchestrate 8 Clio API calls across 5 integration categories, AI extraction, document generation, and client communication.
The pipeline:

Total elapsed time: typically under 30 seconds. Average: 23 seconds.
The system was designed from the start for production reliability. Every external API call has graceful degradation enabled. If the calendar entry fails, the matter still gets populated, the client still gets their email, and the audit trail tells you exactly what succeeded and what needs attention.
Key Results
| Metric | Before | After |
|---|---|---|
| Processing time per intake | 30-60 minutes | Typically under 30 seconds |
| Time reduction | — | 98.6% |
| Cost per intake | $18-$50 (paralegal at $35-50/hr) | $0.15-$0.30 (one Claude API call) |
| Clio fields populated | Manual entry | 18 custom fields, automated |
| Document generation | Manual template, 5-10 minutes | 1.5 seconds, containerized |
| Calendar management | Manual entry, easy to forget | Auto-calculated, auto-created |
| Client communication | Manual email composition | Personalized with dispute narrative |
| Extraction accuracy | Human-dependent | 191-275 structured data points per report, confidence-scored |
Tested against 5 police reports covering rear-end collisions, side-swipes, pedestrian strikes, and multi-vehicle intersections. 100% pass rate. 11 consecutive successful executions after optimization.

How It Works (The Technical Story)
AI Extraction Without OCR
Traditional police report extraction requires an OCR pipeline: Tesseract or AWS Textract for character recognition, image preprocessing for rotation and contrast correction, and a parsing layer to make sense of the output. That is three infrastructure dependencies before you extract a single field.
We skipped all of it. Claude reads the binary PDF directly. No OCR, no image preprocessing, no text alignment layer. The scanned document goes straight to the model and structured JSON comes back.
More importantly, the system reports its own uncertainty. Every extracted field returns a confidence rating: HIGH (clearly legible), MEDIUM (partially readable), or LOW (the model is flagging it for human review). Across 5 police reports, the distribution was 58 HIGH confidence ratings, 6 MEDIUM, and 6 LOW. The LOW scores correlated with genuinely ambiguous data: partially legible handwriting on insurance fields, not false alarms.
That confidence summary gets stored as a Clio custom field. The attorney sees extraction reliability right inside their CRM, not in a separate tool. They know exactly what to trust and what to verify. AI that knows what it does not know is AI that attorneys can actually use.

The Retainer Generation Problem
Clio’s API v4 has no document generation endpoint. There is no /document_templates endpoint. There is no “generate from template” action. We confirmed this across Clio’s official API docs, Zapier community threads dating back years, the Google Groups Clio Developers forum, and Clio’s own support documentation. Third-party tools like Faster Law exist specifically because this gap exists.
So we built our own. A dedicated Docker container running Python and LibreOffice generates retainer agreements from a Word template with conditional logic. When injuries are reported, the document includes injury-specific legal language. When the injury count is zero, different language appears. This is not a static template with blanks filled in — it is context-aware document generation. Generation time: under 2 seconds.
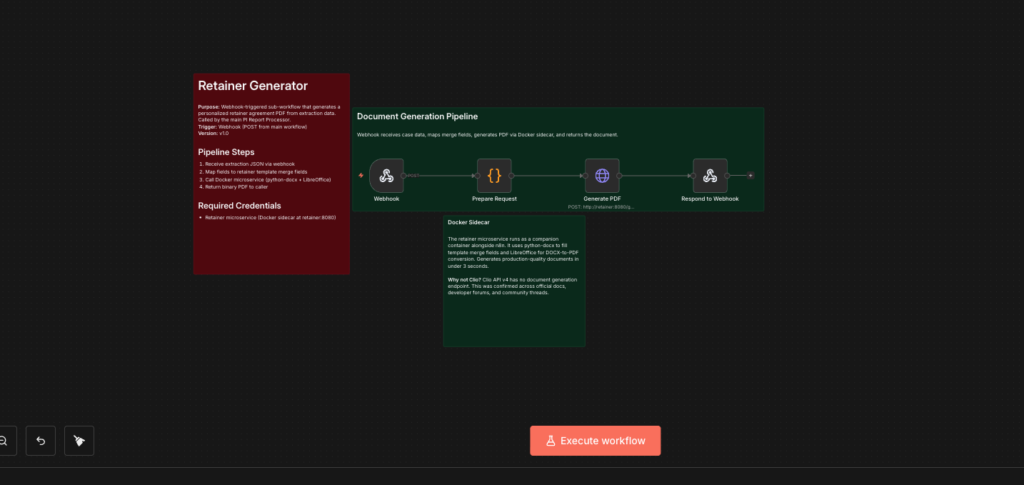
The path to this architecture was not straightforward. The first approach used SSH from the n8n container to the host machine to run the Python generator. It had a 60% success rate — SSH connections from inside Docker are fragile. The second approach tried to install Python and LibreOffice directly inside the n8n container. That failed because the n8n base image uses Alpine Linux with a hardened package manager that blocks additional installations.
The final architecture: a separate container based on Python 3.12 (Debian, full package manager) running an HTTP microservice. The n8n container calls it over Docker’s internal network. Zero SSH, zero shared filesystem. Three containers on a single server: n8n (stock image, unmodified), the retainer microservice, and Caddy for TLS. The n8n image stays stock, which means upgrades are independent. The retainer service is isolated, so a heavy PDF conversion cannot starve the workflow engine.
One more infrastructure detail: the server had 1.9GB of RAM and zero swap. Docker builds with LibreOffice pull over 200MB of dependencies and the conversion itself is memory-intensive. A 2GB swap file was provisioned before any code was written. That was step one in the runbook.
The Undocumented Upload
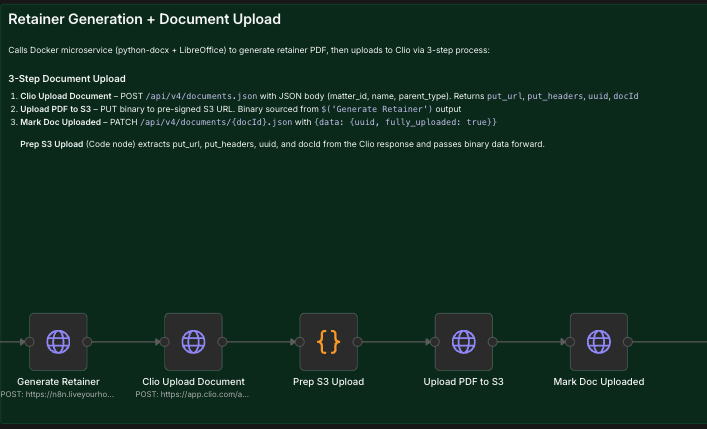
The single hardest integration in the entire pipeline was getting the generated retainer into Clio. The V4 API documentation describes creating a document record. What it does not clearly document is that upload is a three-step process:
Step 1: POST to /documents.json with the filename and parent matter. Clio returns a pre-signed S3 URL and a UUID.
Step 2: PUT the raw PDF binary to that pre-signed S3 URL with the exact headers Clio provided. This is a direct upload to Amazon S3, a completely different host.
Step 3: PATCH the document record with fully_uploaded: true and the UUID. Without this step, you get a successful 201 from Clio and a 200 from S3, but the document never appears in the matter. A ghost record.
We discovered this through systematic testing after multipart form uploads failed, after S3 uploads without the mark step created invisible documents, and after reading implementation patterns in third-party Clio client libraries that handle what the official docs leave out. Three dedicated n8n nodes now execute this sequence reliably.
This is what real API integration looks like. Not the happy path from the documentation.
The Dispute Narrative Engine
This is the feature that makes the client email feel like it was written by someone who actually read the police report. Because the system did read the police report.
The engine parses both drivers’ raw statements from the police report. It applies over 20 regex transformations to convert police jargon into natural language: “V1” becomes “you,” “V2” becomes “the other driver,” “allegedly” gets removed, “struck you” becomes “hit you.”
Then it constructs a collision narrative the client can actually understand:
“While you stated that the other driver was moving from the bus lane into the middle lane and hit you, they are claiming that you were the one in the middle lane and merged into them.”
The system handles three tiers of data availability. Both drivers’ statements present: full dispute narrative. Only one statement: single-perspective summary. Neither statement: generic language that still references the accident date and location. No empty fields, no broken templates.
A small but practical detail: the email includes a scheduling link that automatically switches between in-office appointments (March through August) and virtual consultations (September through February). No manual toggle. The system knows what season it is.

Production Reliability
The custom fields integration uses an idempotent fetch-then-PATCH pattern. The system retrieves existing custom field value IDs before updating, so re-runs update existing values rather than failing with “already exists” errors. A paralegal can reprocess a report after corrections without breaking anything.

ROI Analysis
The direct cost comparison:
| Manual | Automated | |
|---|---|---|
| Per-intake cost | $18-$50 (paralegal at $35-50/hr, 30-60 min) | $0.15-$0.30 (one Claude API call) |
| 20 cases/month | $360-$1,000 in labor | $3-$6 in API costs |
| Annual savings (20 cases/month) | $4,320-$12,000 | — |
But the real ROI is not labor savings. It is cases.
PI firms responding within one minute convert 391% more leads than those responding in five minutes. A firm processing 20 intakes per month through this system is not just saving paralegal time. They are responding to every new case in under 30 seconds. That speed advantage compounds. One additional signed case per month at even a modest recovery could represent tens of thousands in revenue.
The system pays for itself in the first week. The speed-to-lead advantage pays for itself with the first case it helps sign.
What This Means for Your Firm
AI extraction is production-ready for legal documents. Binary PDF processing with confidence scoring means you can trust the output where confidence is HIGH and verify only where it is LOW. The days of choosing between “trust the AI completely” and “verify everything manually” are over. Per-field confidence is the middle ground that makes AI practical for legal work.
Your CRM should be the center of gravity. Every output from this system lands inside Clio: custom fields, calendar entries, documents, communication logs, confidence summaries. Attorneys do not need to learn a new tool or check a separate dashboard. The automation feeds the system they already use.
Speed is a revenue lever, not just a cost reduction. Most firms think about automation as “fewer hours on intake.” That is real, but it is the smaller number. The bigger number is the cases you never lose because you responded in under 30 seconds instead of 30 minutes.
Methodology
This system was built as a rapid proof of concept over 48 hours on self-hosted n8n. It was tested against 5 sample police reports representing different accident types and data completeness levels. The extraction achieved 100% pass rate with 191 to 275 structured data points extracted per report. 11 consecutive successful full-pipeline executions confirmed reliability.
The 48-hour build time is not a limitation. It is a proof point. A production deployment for a specific firm would include jurisdiction-specific SOL calculations, firm-branded retainer templates, integration with the firm’s email and calendar systems, and expanded document type support. The foundation is built. Customization is configuration, not architecture.
Workflow exports and technical documentation are available on request.
HAIBRID Consulting brings consulting rigor to AI automation. We diagnose before we build, measure outcomes not features, and make sure what we deliver actually gets used.
11 questions. Get your personalized AI Readiness Analysis with score, stage assessment, and specific recommendations.